
需要予測AIとは何か? Excelや統計予測との違い
需要予測AIとは、過去の出荷データから機械学習によって将来の需要量を予測する技術です。従来は担当者の「勘と経験」やExcelでの統計計算に依存していた出荷量や在庫補充のタイミングを、AIが自動で算出できるようになりました。
過去データから曜日別・季節別のパターンを学習し、「月曜は出荷量が多い」「12月は通常月の1.5倍」といった規則性を抽出します。担当者の退職とともに失われる暗黙知を、組織全体で活用できる形に変換することができます。
需要予測手法の比較
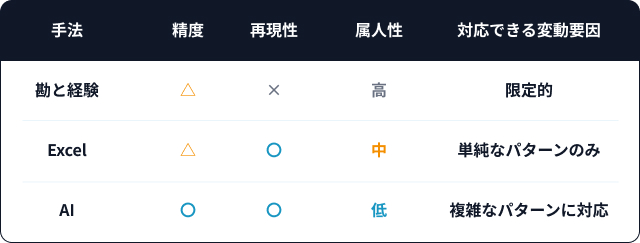
ベテランの勘と経験に頼っていると、退職などによってその知見が失われてしまい、再現性がありません。Excelでの統計による予測は、季節変動など単純なパターンなら対応できますが、複数要因が絡む複雑な需要変動には限界があります。需要予測AIは、複数の変動要因(曜日・季節・イベント・天候など)を同時に学習し、より高精度な予測が可能です。
物流現場で需要予測AIが求められる背景
物流業界では深刻な人手不足が続いています。熟練担当者の退職により、長年の経験で培われた「勘」が現場から失われつつあり、需要予測の精度低下が在庫過剰や欠品を引き起こすケースが増えています。
同時に、EC市場の拡大で需要変動は複雑化しました。曜日、季節性、SNSでのバズ、突発セールなど考慮すべき要因が増え続け、人の判断だけでは対応しきれない状況です。
さらに2024年問題として、トラックドライバーの時間外労働上限規制が強化されました。限られた人員と車両で物流を回すには、事前の需要予測に基づく最適な人員配置と配車計画が不可欠です。
加えて、過剰在庫は保管コストと廃棄リスクを生み、欠品は機会損失と顧客満足度の低下を招くため、精度の高い需要予測が求められています。
需要予測AIで「できること」の具体例
需要予測AIの具体的な活用例を見ていきましょう。
出荷量予測:翌週・翌月の物量を事前把握し、必要人員を計画的に配置します。繁忙期の人手不足や閑散期の過剰人員を防ぐことができます。
入荷量の変動予測:仕入れタイミングと倉庫キャパシティを調整。大量入荷日に事前準備し、荷受け遅延を防止します。
配車計画の自動化:予測出荷量から最適な車両台数と配送ルートを自動計算。早期手配により配送コスト削減と納期遵守率向上が期待できます。
在庫補充の自動化:「いつ・何個発注すべきか」をAIが判断する仕組みです。在庫が一定水準まで減少すると自動発注し、欠品リスクを最小化しながら在庫回転率を高めます。
需要予測AI導入でよくある3つの誤解
需要予測AI導入で多くの企業が抱く誤解を、事前に理解しておきましょう。
誤解1:「AIを導入すれば100%正確に予測できる」
最も多い誤解は、AIが完璧な予測をしてくれるという期待です。AIは確率的に推定を行うツールであり、予測が外れる可能性があります。
突発的なキャンペーン、災害、SNSバズ、競合の値下げなど、過去データにない要因が発生すれば予測は外れるでしょう。重要なのは「100%当たる予測」ではなく、「外れた時の対応」を事前設計することです。
誤解2:「高精度なAIさえ選べば成功する」
精度が高いツールを選べば成功すると考えがちですが、実際には「予測結果をどう使うか」という運用設計が成果を左右します。たとえば、MAPE(平均絶対パーセント誤差)が10%のツールと15%のツールがあったとします。一見すると10%のほうが優れているように思えますが、その予測結果が発注担当者の業務フローに組み込まれていなければ、どちらを選んでも成果は出ません。正確な予測が出ても、参考情報として見られるだけで終わってしまうでしょう。
誤解3:「AIが人を完全に代替する」
AIは判断材料を提供するツールであり、最終的な意思決定は人間が行います。AIと人の役割分担を明確にしなければ、過信や不信が生まれてしまいます。
需要予測AI導入に失敗する3つのパターン
実際の導入現場でよく見られる失敗パターンを紹介します。
失敗パターン1:データ整備を後回しにする
導入を急ぎすぎると、過去データに欠損や不整合が多い状態でスタートすることになります。データの質が低ければ、高性能なAIでも正確な予測はできません。
失敗事例:過去データの不備で予測が機能しなかったケース
・過去2年分の出荷データがあると思っていたが、実際には6ヶ月分のデータに欠損が多かった
・商品コードの付け方が途中で変更されており、同一商品の履歴が追えない
・返品データが記録されておらず、実際の需要量が正確に把握できない
・その結果、AIが学習できず、予測精度が実用に耐えないレベルに
失敗パターン2:「誰が・いつ・何に使うか」が決まっていない
予測結果が毎日出力されても、誰が見て、いつまでに、どの業務判断(発注・配車・人員配置)に反映するかが決まっていなければ、その予測結果は使われません。これでは、従来の勘と経験による判断に戻ってしまいます。
失敗事例:MAPE 15%の予測が「見るだけの資料」になったケース
・AI導入後、毎日翌週の出荷量予測レポートが自動生成された
・予測精度はMAPE 15%(業界としては良好な水準)を達成
・しかし、発注担当者の業務フローは「月1回、月末に翌月分をまとめて発注」のまま
・毎日届く予測レポートは「参考までに見る」だけで、実際の発注判断には使われなかった
・その結果、AIは「見るだけの資料」となり、在庫過剰・欠品は改善されず
失敗パターン3:自社に合わない製品を選定してしまう
既存のWMSやERPと連携が難しい製品を選ぶと、予測データを手作業で転記する手間が発生します。また、自社特有の業務ルール(優先出荷、安全在庫の基準など)に対応したカスタマイズができない製品では、現場に合わない予測結果が出てしまうでしょう。導入前にシステム連携の可否や業務ルールへの対応力を確認しておく必要があります。
失敗事例:システム連携の不備で手作業が増えたケース
・高精度を謳うAIツールを導入したが、既存のWMSとAPI連携ができない製品だった
・予測結果をExcelでダウンロードし、WMSに手入力する作業が毎日発生
・特定の得意先向け商品は「優先出荷」するルールがあったが、AIツールではカスタマイズできない
・その結果、現場の作業負荷が増え、予測結果も実態に合わず、半年後に利用停止
需要予測AIが向いている企業・向いていない企業
すべての企業に需要予測AIが適しているわけではありません。自社の状況を客観的に評価し、導入タイミングを見極めましょう。
向いている企業
需要予測AI導入に適しているのは、過去1年以上の出荷実績データがデジタル形式で整備されている企業です。また、需要変動に規則性(季節性・曜日性・イベント連動性など)があることも重要です。
さらに、予測結果を活用できる業務フロー(発注・配車・人員配置など)が存在する、または新たに設計できる体制があることも大きなポイントです。
向いていない企業(導入を急ぐべきでない)
過去データが不足している、またはデータの質が低い企業は、まずデータ整備から始めましょう。また、突発的な大口案件が中心で需要がランダムな企業も、AI導入の効果は限定的です。
予測結果を使う業務フローが存在せず、それを設計する投資意欲もない企業では、導入しても活用されないまま終わる可能性が高いでしょう。
「使われる予測」にするための運用設計のポイント
需要予測AIを活用するには、精度以上に「予測をどう使うか」の運用設計が重要です。
まず、予測結果を誰が・いつ・どの業務判断に使うかを明確に定義しましょう。たとえば「毎週月曜9時に発注担当者が予測レポートを確認し、10時までに発注数を決定する」といった具体的なフローを設計します。
次に、人の判断とAIの組み合わせ方を決めます。推奨されるのは「AIが提案し、人間が承認する」フローです。AIが提案した予測値について、担当者が確認した上で最終判断を行うことで、過信も不信も防げるでしょう。
さらに、予測結果を発注・在庫・輸送判断に自動連動させる仕組みを構築することで、予測が確実に実務に反映されます。予測と実績の乖離を定期的に分析し、パラメータを調整することで、予測精度は徐々に向上していくでしょう。

よくある質問(FAQ)
Q.どのくらいのデータ期間が必要?(1年で足りる?)
最低でも1年分のデータが必要です。季節性(夏と冬の差、年末年始の需要増など)を学習するには、12ヶ月の周期を1巡以上カバーしていなければなりません。理想的には2〜3年分あると、年ごとのばらつきも加味した安定的な予測が可能になります。ただし、データ量だけでなく「欠損の少なさ」や「粒度の統一」も重要です。期間が短い場合は、対象を季節変動の小さい商品群に絞ってスモールスタートする方法もあります。
Q.SKUが少なくても効果はある?
SKU数が少なくても効果は得られます。むしろ、SKU数が少ないほど1品目あたりの出荷データが豊富になり、予測精度が高くなりやすい傾向があります。一方で、SKU数が極端に少なく(例:10品目以下)、かつ各SKUの出荷頻度も低い場合は、統計的に意味のあるパターンを見つけにくくなります。まずは出荷頻度の高い主要SKUから導入し、効果を確認しながら対象を広げていくのがよいでしょう。
Q.需要がランダムな商材はどうする?
突発的な大口受注やスポット案件が中心の商材は、過去データに規則性が少ないため、AIによる予測が難しい領域です。このような商材では、需要予測AIを「当てにいく」のではなく、安全在庫の水準設定や異常値検知(通常と大きく外れた注文の早期アラート)といった補助的な使い方が有効です。すべての商材を一律にAI予測の対象にするのではなく、規則性のある商材とランダム性の高い商材を分けて管理する設計が重要になります。SBフレームワークスでも、商材特性に応じた仕分けとそれぞれに適した管理手法の設計を支援しています。
Q.予測は週次と日次どちらが良い?
業務の意思決定サイクルに合わせて選ぶのが原則です。たとえば、発注が週1回であれば週次予測で十分ですし、日々の人員配置や配車計画に使うなら日次予測が必要になります。一般的には、まず週次予測から始めて運用を安定させ、その後必要に応じて日次に細分化するステップが推奨されます。予測の粒度を細かくするほどデータ量の要件も高くなるため、自社のデータ蓄積状況と照らし合わせて判断しましょう。
Q.PoCで見るべき指標は?(精度以外に何を見る?)
精度指標(MAPEなど)はもちろん重要ですが、それだけで導入判断をすると失敗しやすくなります。注目すべきは「予測結果が業務で使えるか」という観点です。具体的には、予測結果の出力タイミングが業務フローに間に合うか、担当者が理解・活用できる形式で提供されるか、既存システムとの連携に問題がないか、といった実運用面の検証が不可欠です。また、予測が外れた場合のリカバリー手順まで含めてPoCで確認しておくと、本番導入後のトラブルを大幅に減らせます
まとめ
需要予測AIは「魔法の杖」ではなく、人と組み合わせて使うツールです。導入前に誤解や失敗パターンを理解し、自社の適合性を冷静に判断しましょう。
「当たる予測」より「使われる予測」を目指すことが重要です。予測精度より、予測結果が実際の業務判断へ確実に反映される仕組みを作ることが、成果を左右します。
データ整備と運用設計は、予測精度以上に重要です。過去データの質を高め、「誰が・いつ・何に使うか」を明確にすることで、AIは初めて現場で機能します。特定の拠点や商品でスモールスタートし、効果を確認しながら段階的に展開することをお勧めします。







需要予測AIは「導入すれば当たる」ものではありません。
予測精度以前に、過去データの整備状況(欠損・粒度・定義のブレ)と、予測結果を誰がどう使うかの運用設計が揃っているかで、成果が決まります。
たとえば、「AIが翌週の出荷量を予測した」としても、それを誰が見て、何時までに、どの業務判断(発注・人員配置・配車計画)に反映するかが決まっていなければ、その予測結果は使われずに終わるでしょう。
SBフレームワークスでは、ツール導入ありきではなく、AI前提の業務設計(活用フロー・責任分界)とデータ設計(粒度・更新頻度・連携先)から整理して進めることを重視しています。使われない予測は、存在しないのと同じです。